

マーケター必読「ブランディングの科学」の基礎を約10000文字でまとめました

マーケティングの仕事に従事しているなら、絶対に目を通しとかなあかんと勝手に感じている書籍の1冊が「ブランディングの科学」(著:バイロン・シャープ、刊行:2018年7月)です。
刊行後、各地で賛否両論の嵐が巻き起こったので、皆さんご存知でしょう。好き嫌いの程度はあれ、無用の知識ばかりだと思ったマーケターは意外と少ないのではと感じています。
インサイト発掘支援でお馴染みのデコム在籍時、代表の大松さんが某PGマフィアから「この書籍について大松さんと語りたい」とオファーを貰ってから慌てて社内のマネージャー陣総出で読み漁った…という記憶があります。
知る人ぞ知る名著ではないでしょうか。
刊行から既に2年が経過しましたが、その内容自体は「法則は全て暗記した方が良いレベル」(大松さん)と評されるほど。年末年始にまとまった時間ができたのもあって、改めて読み直しました。
本noteは、改めて読み直したまとめです。
「ブランディングの科学」が導き出す結論
さて、いきなり結論です。最近は、歌だっていきなりサビ、ドラマだっていきなりクライマックスです。早送りできる時代ですから、冒頭に結論書かないと読み飛ばされちゃうんですよね。
「ブランディングの科学」の結論、もっとも言いたいであろうことは巻末の第13章「究極の世界」に記されています。以下抜粋します。
マーケットシェアを含めてすべてのマーケテイング指標がある1つのことを反映していることが示唆される。それはブランドの人気度(popularity)だ。ブランドによって人気度には差があるが、この人気度こそすべての原点だ。お互いに競合関係にあり同等の人気度を持つブランドはその指標も類似している。
このパターンは非常に安定しており、ある数理モデルを使って、本書で紹介した法則の多くを予測できる。そのモデルはNBD(負の二項分布)ディリクレモデルと呼ばれるもので(通常はディリクレと略される)、これでブランドの選択率と購買率を予測する。
「人気度」こそがセンターピン(核心)というのがバイロン・シャープ氏の主張です。ただ、「人気度」という指標が、好き・嫌いの一般的な人気投票なのか、或いは知っている・知らないの認知度を指すのかが分かりにくいと感じるかもしれません。
引用文の後半で「ブランドの選択率と購買率を予測」と書いているので、人気度とは選択率とも読み取れます。
「人気度」を分かりやすく説明しているのが、バイロン・シャープ氏が紹介した負の二項分布をメインとして据えている「確率思考の戦略論」(著:森岡毅・今西聖貴、刊行:2016年6月)です。以下抜粋します。
パンケーキを食べる回数、歯磨き粉の購入回数、本の貸し出し回数は、それぞれ独立した行為です。それぞれお腹が空いた時に好みの食事をとり、それぞれ必要な時に歯磨き粉を買い、それぞれ必要な時に図書館に行き好みの本を借ります。これらは、それぞれのカテゴリーに対する消費者のプレファレンス自体の違い(消費頻度や購入回数などの見た目の違い)はありますが、プレファレンスに基づいてそれぞれのカテゴリーの構造が形成されるという全く同じ規則に従っています。
プレファレンス(Preference)とは、消費者のブランドに対する相対的な好意度、選好性を指しています。バイロン・シャープ氏の言う「人気度」とは「他ブランドと比べてどれぐらい好きか=人気があるか」と解釈しても良さそうです。
森岡さんは「我々が奪い合っているのは消費者のプレファレンスそのもの」「プレファレンスによって購入回数も支配されている」と断言しています。その理由として、NBD(負の二項分布)ディリクレモデルをあげています。
【注】モデル自体の詳細な説明は以前にまとめていますので、そちらを参照いただければ幸いです。以降、ある程度はモデルに対する理解がある前提で書き進めています!
NBD(負の二項分布)ディリクレモデルは以下の数式で表現されます。

赤玉と白玉が混ざった袋にN回手を入れ、r回赤玉が出る確率はPrと表現できます。鍵を握るのはMとKです。Mは「N回中赤玉が出る平均回数」、Kは「購入確率の分布のパラメータ」です。すなわちMは選択率、Kは購買率と言えるでしょう。
森岡さんは次のように説明します。
我々が着眼すべき戦略の焦点はこのNBDモデルの式中のMであり、それはすなわちプレファレンスを伸ばすことです。繰り返しになりますが、Mとは「自社ブランドへの1人あたりの投票数」のこと。つまり、戦略の本質とは、市場全体の中で自社ブランドへの1人当たりの投票数をどう増やすかを考えることに他なりません。
ブランドの人気度とは、すなわち「自社ブランドへの1人あたりの投票数」と考えて良さそうです。「とても気に入った」「大好き」「すごく愛している」「最高だ」など、コメントの内容はともかくとして、何度でも投票できる点においてはAKB総選挙と同じ類とも言えそうです。
ところで「自社ブランドへの1人あたりの投票数」という言葉を、別の言葉に言い換えてみましょう。「確率思考の戦略論」から以下抜粋します。
例えば、選挙の時に、現実社会のように投票する時期や投票数(1人1票)などのしがらみのない世界で投票することを想像してみてください。AKBの総選挙のような世界です。その世界では一定期間内に、いつ、誰に、何票、投票してもしなくても自由です。その世界で一定期間に自社ブランドに投票された全ての投票数を、選挙権のあった全ての人間の頭数で割ったもの、つまり「(一定期間内の自社ブランドに対する)1人当たりの投票数」、これがMです。
「自社ブランドへの1人あたりの投票数」とは「自社ブランドへの平均投票数」とも言い換えれます。M=「N回中赤玉が出る平均回数」と同じです。
仮に100人いたとします。1人が100票を投じ99人が投票しない(垂直志向)のと、100人がそれぞれ1票を投じる(水平志向)のとでは「平均投票数」は同じです。
ここで「自社ブランドへの平均投票数」を「自社ブランドの平均購入頻度」に置き換えて考えてみましょう。たった1人が1票しか投票してくれなかった場合、次回の投票集計では、購入頻度を増やすのと、購入者数を増やすのとどちらが大事でしょうか?
「どちらもやれや」って話かもしれませんが、アプローチが違いますし、限られたリソースの中では、いずれかに全フリした方が良いでしょう。
プレファレンス(好意度)を高めろと言っているのだから前者の垂直志向だと思われるでしょうか。しかし「ブランディングの科学」でバイロン・シャープ氏は後者の水平志向だと主張します。
どのように「投票数」を増やせばいいか?
「ブランディングの科学」では、英国や米国におけるコカ・コーラ購入者の購入頻度分布を紹介しています。「確率思考の戦略論」を読んだ人であればその分布がNBD(負の二項分布)ディリクレモデルとほぼ一緒だと気付くでしょう。
グラフについては永井さんの記事に登場するので、そちらを参照されると良いかもしれません。
分布は以下のようなロングテールのような形を示します。仮にM=1だったとして、K=0.5の場合、K=2の場合の分布を作成しています。この図を元に言えば購入者の大半は、ごくまれにしか商品を買ってくれないライトユーザーだと言えるでしょう。
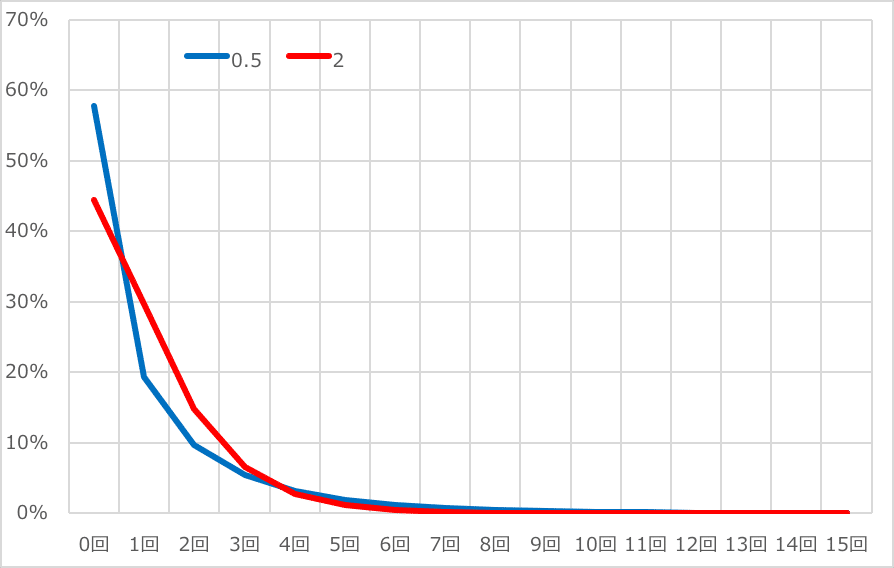
分布は均一では無いがゆえに、ロングテールの尾っぽに平均購入頻度が押し上げられます。結果的に分布の実態と乖離を起こします。「ブランディングの科学」から抜粋します。
マーケターは消費者がなかなか自分のブランドを選んでくれないことをつい忘れがちだ。そしていつも平均購入頻度指数の低さに驚いている(そして、この指数を簡単に増やす余地は大いにあると間違った結論に至っている)。さらに残念なことに、この平均値が典型的な購買客の購入頻度と比較して実は大きいということに気づいているマーケターは少ない。
なぜ選んでくれないのか。0回〜1回が圧倒的に多いのか。バイロン・シャープ氏は「彼らがそもそもそのカテゴリー自体での購入頻度が少なく、かつ彼らは他のブランドも購入しているからだ」と断言します。
つまり偶然買った消費者、或いは1回買ったことすら忘れてしまう消費者がいっぱいいるのです。そうした人たちに「私たちのブランドもっと買ってよ」とメッセージを投げかけて購入頻度を高めても、CVR0.1%程度に留まるのは当然なのかもしれません。だって、そもそも興味があったわけではないから無視もされます。
もっと買ってもらう垂直志向の非現実性を確かめるために、「ブランディングの科学」ではマーケットシェアが大きいブランドとマーケットシェアが小さいブランドと比べて、前者の方が「購入頻度」が多いのかを確かめます。以下抜粋します。
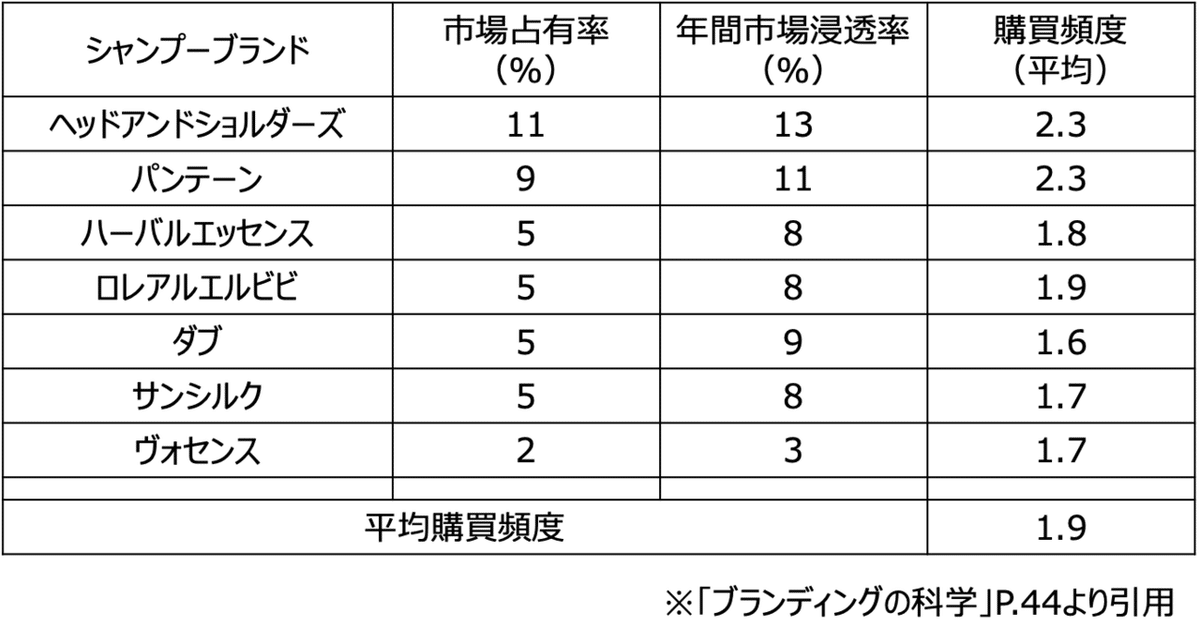
表から分かる通り、ヴォセンスの約5倍マーケットシェアが大きいヘッドアンドショルダーズを比較すると、購買頻度は多少高いですが、それよりも年間市場浸透率(その期間にそのブランドを少なくとも1回は買ったかを表す)がかなり多いと分かります。購買頻度が全く一緒とは言いませんが、市場占有率を高めるためには頻度より客数が重要だと分かります。
平均購買頻度が少しだけ高まる理由はシンプルです。人気度が高まっているからであり、すなわちM=プレファレンスが高まっているからです。もっと言えば0回の消費者が占める割合が相対的に低いからです。さきほどのNBD(負の二項分布)ディリクレモデルが示す通り、Mが高まればKも高まり、分布は右側へ偏ります。その分、平均購買頻度は少しだけ高まるのです。
1回だけ購入するライトユーザーが爆増しているということは、すなわち水平志向状態が生まれていることに他なりません。
プレファレンスを高めるとは、既存の消費者に向けて(垂直志向)ではなく、市場全体に向けて(水平志向)なのです。
垂直志向の手法自体を否定するつもりは全く無いですが、売上の大きい会社と、比べたら小さい会社を比較してNBD(負の二項分布)ディリクレモデルにほぼ合致する以上、水平志向が「よりいっそうの売上を伸ばす手法として極めて再現性がある」とは言えるでしょう。
※「ブランディングの科学」で取り上げた法則が効かない市場については、「ブランディングの科学2」で紹介されています。これは、また次回にまとめたいと思います。
成長し続けるためには、人気度を高め続ける=ライトユーザーを獲得し続けるしかありません。最終的にはブランドが属するカテゴリーを利用する日本中、いや世界中の消費者をターゲットにしなくてはいけなくなります。
それでも、どこかで限界が来ます。「嫌い」「絶対に使いたくない」といったアンチユーザーは必ずいるからです。獲得できなくなったポイントが売上の限界となるでしょう。
見方を変えれば、ブランドが成長し続けるために、カテゴリー全体の消費者は1百人よりも1千人、1千人よりも1万人と大いに越したことはありません。
これこそ「なぜ市場を定義するのか」「なぜセグメンテーションで区切るのか」に対する解です。ターゲットを誰にするのかは重要な課題ですが、よりカテゴリー(市場)全体の消費者が多くなるように、かつM=プレファレンスが高そうな消費者が集まるようにセグメンテーションするためです。カテゴリーを狭めるのは、自らの首を絞めるだけです。
ちなみに、森岡さんは「確率思考の戦略論」で次のように説明します。
ブランドのプレファレンスを伸ばそうとするときに、実戦経験の浅いマーケターがよくやってしまう過ちは、既存の特定の消費者ターゲットの中でのプレファレンスを伸ばすことで頭がいっぱいになってしまうことです。しかし、我々が肝に銘じておくべきは、あくまでも市場全体での自社ブランドへのプレファレンスを上げることです。もっと言えば、それはUSJの「M」を増やす戦い。USJのチケットを買うファンの人数を、市場全体でどうやって増やしていくのか? という勝負なのです。
森岡さんも、当時のUSJが独身女性に集中していた消費者を、カテゴリー全体の消費者に到達させようとしていました。
だからこそ消費者のインサイトが大事になります。プレファレンス、すなわち人気度が高い商品・サービスであるためには、消費者の「そうそう、これが欲しかった!」と口にするインサイトを突く必要があります。そうすることで、ノンユーザー(未顧客)がライトユーザーとなる端緒が開けます。
ちなみに、発掘したインサイトは最後に定量調査(n=600ぐらい)にかけます。デコムで設けたノルム値を超えたインサイトのみOKとし、顧客に提供します。つまり、定量調査でより多くの人から好意的に評価されたインサイトは、プレファレンス、すなわち人気度が高いという見立てです。
なぜ「垂直志向」が否定されるのか?
NBD(負の二項分布)ディリクレモデルで考えれば、マーケットシェアが大きいブランドと小さなブランドで平均購買分布に大きな差が生まれない理由はイメージが出来るのですが、いったんそうした数式を忘れて、なぜ垂直志向をバイロン・シャープ氏が否定するのかを考えます。
理由はシンプルで、多くのブランドが何らかのカテゴリに所属していて、一方の消費者は「カテゴリが提供する便益」を期待しているから、よほどで無い限りは「このカテゴリではこのブランドしか買わない!」という気持ちにならないからです。だから、ブランドを買っているのだけれど、競合のブランドも同じように買うのです。
ちなみに、皆さんは「このカテゴリでは、このブランドしか買わない!」って商品はあるでしょうか。もしあったとしても、せいぜい1つか2つではないでしょうか?
自宅をくまなく探してみましたが、嫁の使っている化粧品関係、私の仕事関係の小物、冷蔵庫の中の食品類ですらそうでした。だいたいは複数のブランドを使っていました。唯一、このカテゴリではこのブランドだけだよねと気付いたのは「S&B本わさび」です。
つまり自社ブランドと競合ブランドで顧客は重複しているのです。「ブランディングの科学」から抜粋します。
自社ブランドの顧客が競合ブランドの顧客と類似している点は多く、また逆に、競合ブランドの顧客が自社ブランドの顧客と類似している点も多い。これは、自社ブランドが競合ブランドの顧客を獲得するチャンスが大きいことを示唆している。だからこそ、市場全体をターゲットにするべきだ。
カテゴリを狭めて定義すると、楽天市場のように「◎◎の分野でNo.1」という称号が得られます。ただし実際には狭いカテゴリでNo.1になるより、より広いカテゴリでNo.3を目指した方が売上に効く場合は往々にしてあります。
しかし、私自身がそうであるように「カテゴリを広げて市場を見据える」ことは勇気がいります。低いシェア率を見ると「私たちのような弱者は強者に食われるだけじゃないか?」と怯えてしまいます。
しかし、朗報ですが、カテゴリがもたらす機能的便益がだいたい同じであれば、顧客は重複します。競合ブランドを購入している人たち全てが自社ブランドを購入しない、なんて現実的にはあり得ないのです。「ブランディングの科学」から抜粋します。
顧客基盤に成長の可能性があるということは、あなたのブランドの成長を抑制しているものがないということだ。競合ブランドの顧客基盤は、あなたのブランドの顧客基盤と類似しているので、将来的にはあなたのブランドの顧客となる可能性を秘めている。もしあなたのブランドの顧客基盤が競合ブランドの顧客基盤とまったく異なっていれば、あなたのブランドはある特別のタイプの消費者群に適しているということになり、それは、あなたのブランドがニッチを満たしていることを意味する。もしもそのようなことになれば、マーケティング部門の仕事はそこで終了だ。
競合と違って当然なのは機能まで、むしろ顧客基盤はお互いにシェアし合っているのが当然です。
競合とは敵同士でありながらも、同じ顧客基盤を耕している点ではむしろ同士なのです。複数社いた方が、勝手に市場を拡張してくれるおかげで「おこぼれ」に預かれる場合もあります。
顧客基盤の重複性を確かめるために、「ブランディングの科学」ではあるアイスクリームブランドの「重複度」を確かめています。以下抜粋します。

縦軸は、上に行けば行くほどブランドの規模(シェア)の大きさを表しています。つまりブランドの顧客基盤は、マーケットシェアに応じて競合ブランドの顧客基盤と重複すると言えます(表を見る限り、多少の逸脱はあるようですが)。「ブランディングの科学」から抜粋します。
1.どのブランドも顧客基盤の多くを最初規模のブランド(マーズ)よりも最大規模のブランド(カルト・ドール)と共有している。
2.どのブランドも特定のブランドと同等の割合で顧客基盤を共有している。たとえば、すべてのブランドがカルト・ドールと顧客の40%(±数%)を共有している。
大きいブランドは小さいブランドに比べて、買われる可能性が高いことを示しています。このことも、大きいブランドは小さいブランドよりも年間市場浸透率が高いことを指しています。知っているブランドこそ選びたい、少なくとも選択肢に残るということでしょう。
垂直志向とは、こうした数字にあって「他のブランドも購入した購買者の割合」を全て下げる行為を指します。
ある特定の市場で、もしかしたら可能なのかもしれませんが(繰り返し何度でも何度でも主張しますが)垂直志向にかかる労力のリターンと、小さいブランドから大きいブランドに成長するために水平志向にかかる労力のリターン、明らかに後者の方が低燃費・低価格ではないでしょうか。
なぜ広告を出稿するのか?
大規模で誰もが知っているブランドであっても、その購入者の大半が極端に購買頻度の低いライトユーザーであり、したがって思い出さなければ買われない場合は結構あります。
こちらの記事に詳細が掲載されていますが、パッケージのデザインを変えるだけで「当時指標にしていた一部コンビニでのシェアが約47%から一気に約38%と10%ほど下落」したのです。前代未聞というか、いかに消費者はその瞬間の気分で商品を購入するかがよく分かります。
どれだけ確立したブランドであっても、広告のターゲットはノンユーザーやライトユーザーなのです(ただし、ここで言う広告はダイレクトレスポンス広告や検索広告を除く)。「ブランディングの科学」から抜粋します。
コークの広告の目的は、私たちがすでに知っていることを思い出させることである。そうすることで、明日のコーク購買の可能性を高めようとしている。これが機能すれば、明日の購買率は、ほとんどゼロの状態(300分の1)から、それを少し上回る状態(300分の2)へと変化する。この変化は非常に小さく、気づきにくい。微妙すぎて認識できない。広告の影響力は小さいと言われる所以である。しかし、広告を見たすべての消費者の購買傾向を300分の1から2に増大したとすると、コカコーラの売上高は2倍になる。
良い広告とは、消費者の購買行動に影響を与える広告なのです。記憶構造が刷新されて、メンタル・アベイラビリティ(ブランド想起の高さ)が向上します。
「ただし多くの広告は処理すらされず、ブランドと紐づいて記憶されない」とバイロン・シャープ氏は主張します。良い広告とは何かは分かっているけど、それをどう再現するかが分からない、とも言えます。失敗したくて失敗するマーケターなんて一人もいないので、再現できない何らかの理由があるはずです。
バイロン・シャープ氏は広告のセンターピンを「記憶」だと主張します。「ブランディングの科学」から抜粋します。
記憶は広告とブランド選択の橋渡し役を務めている。マーガリンなどの頻繁に購入される商品でさえも購入頻度は平均して年に8回ほどで、ほとんどのブランドが年に1、2回しか購入されていない。
消費者が自分のブランドに気づいてもらわねば困る。消費者の目に留まり検討してもらえるかどうかは、そのブランドの購入を左右する重大な要因だ。消費者の選択肢の幅がいかに狭いかを考えると、ブランドが消費者の目に留まり検討してもらえることは少なくとも一か八かのチャンスよりはましだ。つまりブランドの売り上げは、基本的には、消費者の選択肢の1つとして生き残れるかどうかによって決まる。
アメトーーーークの家電芸人を一躍有名にした「買いたい時が買換え時」という名セリフですが、「買いたい時」に名前すら浮かばないブランドじゃダメなのです。
多くの消費者は、私自身もそうなのですが、買う前に、選択肢に考慮すらしない決断をまず下しています。「買うために選ぶ」ために「これらは買わない」と決めているのです。「これらは買わない」とは、単純に知らないだけでなく、知っているけど思い出せない場合も含みます。
広告は、これが欲しいと感じたり、こういう便益が欲しいと思ったり、そうした瞬間に呼び起こされる記憶に紐付いて登場しなければならない、という指摘は「それはそう」「だけどなかなか難しい」と背筋が凍る思いです。
メンタルアベイラビリティとフィジカルアベイラビリティ
「人気度」に始まり、長々と解説をしてきましたが、私たちマーケターが何を為すべきかは以下に要約されます。「ブランディングの科学」から抜粋します。
マーケターの主たる仕事はブランドを買い求めやすくすることだ。そのためには他の何よりも、メンタル・アベイラビリティとフィジカル・アベイラビリティが重要だ。ブランドは、このメンタル・アベイラビリティ(ブランド想起の高さ)とフィジカル・アベイラビリティ(購買機会の高さ)の構築を競い合っているようなものだ。
同じことを繰り返しますが、まずは「買って貰う」よりも「候補に選んで貰う」ことが大事です。「ジャケ買い」など直感的に購入される場合もあるでしょうが、大半はそうではありません。
「確率思考の戦略論」では、次のように紹介されています。
消費者の頭の中には、今までの購入経験から買って良いと思ういくつかの候補となるブランドがあるということです。それらの購入候補であるいくつかのブランドの組み合わせを「Evoked Set」とマーケティング用語で呼びます。(略)
買っても良いと思っているその4つのブランドのまとまりの中からその時々で買うブランドをランダムに選んでいるのです。消費者は誰しも「エボークト・セット」を持っており、プレファレンスに基づいてそれぞれのブランドを購入する「確率」が決まっているのです。(略)購入の確率は、その人の経験に基づいた好み(プレファレンス)をダイレクトに反映しています。
メンタル・アベイラビリティを高めるとは、すなわち覚えて貰う、と同時に選ばれる可能性を高める(=その人の中での人気度を高める)に他ならないでしょう。
多くのユーザーに、24時間365日ずっと自社ブランドのことを考えて貰うのは事実上不可能に近い(あったとしても極めてごく少数)。ただし記憶と広告の力を借りて、ブランドと日常シーンを紐付けてシェア・オブ・マインドを広げることは可能だと思われます。
とはいえ、覚えていても人気が無ければ選ばれません。認知度と売上に相関が見れない時、或いは外れ値を示した時は「人気度」で見ると良いかもしれません。
もう1つのフィジカル・アベイラビリティは購入のしやすさです。私がいくらマクドナルドが好きだからって、歩いて2km先にある店舗まで高い頻度で買いに行こうとは思いません。あるいは店頭に置いていないからといって、ある店舗まで探すとは限りません。
アプリであれば、一般ワードで検索して1位を占めることがフィジカル・アベイラビリティが高いと言えるでしょう。それぐらい「買いやすい」というのは重要なのです。
「買いたい時が買換え時」なのに、近くの店舗に無ければ買われません。今の時代ならECサイトがありますが、「なんとなく欲しい」といった曖昧な感情であったなら、ECサイトに辿り着くまでに「やっぱりいいや」と気持ちが削がれてしまうのではないかと考えています。
まとめ
これまで紹介してきた内容を、「ブランディングの科学」では法則と名付けてまとめています。本書の最後のまとめは法則の紹介にしたいと思います。
ダブルジョパディの法則
マーケットシェアが低いブランドは購買客数も非常に少ない。
顧客基盤が類似する
競合ブランドの顧客基盤と自社ブランドの顧客基盤は非常に類似している。
購買重複の法則
ブランドの顧客基盤は、マーケットシェアに応じて競合ブランドの顧客基盤と重複する(大規模ブランドとの顧客共有率は高く、小規模ブランドとの顧客共有率は低い)。もし、一定期間内にあるブランドの購買客の30%がブランドAも購入するとすれば、どの競合ブランドもその購買客の30%がブランドを購入する。
NBDディリクレ
カテゴリー内の購買客の購買頻度や購入ブランドについて、その傾向にどのような差異が生じているかを明らかにする数理モデル。このモデルが前述の法則の多くを正しく解説し説明してくれる。
いいなと思ったら応援しよう!
