

日曜データサイエンティストのススメ(covid-19のデータ分析)

データサインエンスは誰でも行える時代
以前、このnoteに、
という寄稿をしました。その中で、紹介した「R」ですが、どれくらいの人が興味を持ってくれただろうか?このRとは、多くのデータサイエンティストが使っている統計ソフトで、なんと無料だ。
日経新聞のデジタル版には、
という、データサイエンティストが参考になる、「データ・ジャーナリズム」のコーナーがあるが、これに似たことは、誰でも行える。
以前は、データを持っている人が、この世の中の勝者に近づくことが多かった。しかし、デジタル時代の今は、データを人より早く、多く持つことは、それほど優位に働かない。むしろ、データを観察・分析をして、そこからどのような行動アイディアを考えるかが重要だ。
そして、そのデータの観察・分析は誰でも行えるので、具体的な方法を少し、紹介しよう。
RとRStudioを自分のパソコンにインストールしよう
まずは、データ分析の環境を整えよう。方法は、簡単だ。自分のパソコンに、RとRStudioをダウンロードして、インストールするだけだ。ソフトへのリンクは、
私のサイトにLinkを貼っておいた。
自分のパソコンに、ソフトをインストールしたことない方もいるだろう。そんな方は、YouTubeで、「Rのインストール」「RStudioのインストール」などと検索して欲しい。動画で丁寧にインストール方法が確認できるはずだ。
あとは、RStudioの使い方を少し、学んでから、以下の部分に進んで欲しい。
RStudioでグラフを描く準備
標準のRの機能でも、多くの分析が可能だが、少し便利な、tidyverseというライブラリーを導入することをお勧めしたい。
そのために、RStudioに
install.packages("tidyverse")と入力するだけである。無事にインストールされれば、
library(tidyverse)と入力すると、画面の方から、 青い字でlibrary(tidyverse)、返事が出れば、準備完了である。
動作しているか確認するために、意味不明だと思うが、次のコマンドを入力して、グラフが表示されるか確認してみよう。
ggplot(data = diamonds)+geom_histogram(mapping = aes(x=carat))これを実行すると、以下のようなグラフが、左の画面に表示されるはずである。
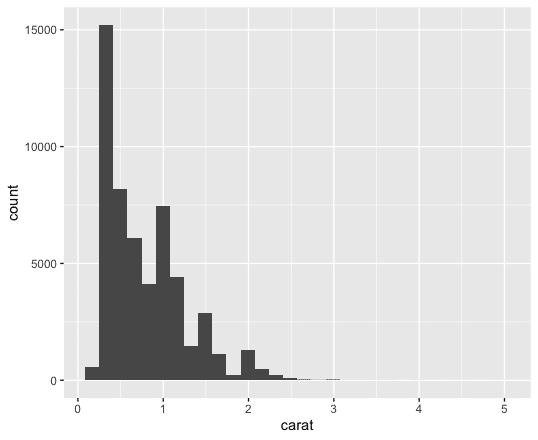
このグラフは、Rの中に標準で用意されている、ダイヤモンドのデータで、横軸に「カラット」、縦軸に「ダイヤモンドの個数」を数えたものである。グラフがすぐ表示されるが、実際には5万行を超えるデータを集計して、グラフを表示している(データの説明は、The diamonds dataset などを参照ください)。
これで、準備完了である。そして、このグラフを観察するだけでも、多くのことがわかる。ダイヤモンドは天然石が多いだろうが、なぜかカラッとでは、1,1.5,2カラット付近は、周りより個数が多い。そして、当然大きなダイヤモンド(カラットが大きい)が少なくなる。このような観察は、データサインエンスの入り口である。
実は、私たちは日常で、データを正しく眺めないことによる、判断ミスが多い。データサインエンスとは、複雑な数学、統計ではなく、正しくデータを眺め、そこから何が起きているのかを考えることが重要なのだ。
東京都が公開しているCovid 19のデータを観察しよう
では、別なデータを観察してみよう。東京都は、「新型コロナ感染症対策サイト」で、「最新感染動向」に関して、データを公開している。そして、ここで公開されているデータ以外にも、「東京都オープンデータカタログサイト」でも多くのデータを公開している。そのデータの中に、「東京都_新型コロナウイルス陽性患者発表詳細」のデータを使って、以後簡単な分析例を紹介しよう。
残念ながら、Rは、あまり日本語の取り扱いが上手でない。そこで、上記「東京都_新型コロナウイルス陽性患者発表詳細」から、日本語のデータを取り除いたデータを、私の方で方で用意した。データをダウンロードしてみて欲しい。csv形式でデータが保管されるはずだ。
このデータを、covid-20210919.csvという名前で、保管し、自分のRのフォルダーにしまって欲しい。自分のフォルダーは、
getwd()で確認できる。このフォルダーにこのファイルをコピーさせてみよう。
そして、このデータをRで使えるようにして、簡単なグラフを書いてみよう。
covid <- read.csv("covid-20210919.csv")
ggplot(data = covid) + stat_count(mapping = aes(x=sex))これを実行すると、東京都で、2020/1/24から、2021/9/19までに公表された感染者の「性」別の感染者数のグラフが表示される。
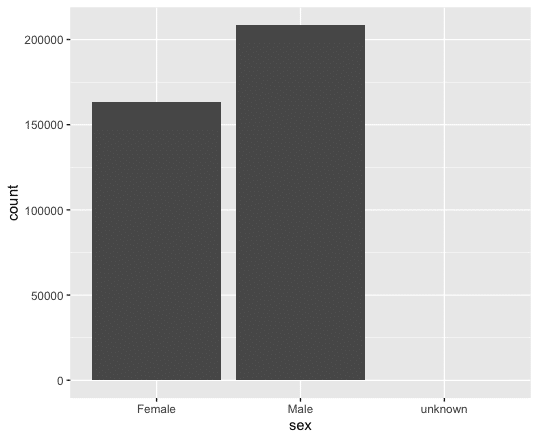
皆さんもよく知っているように、男性(Male)が、女性(Female)の感染者数が多いことがわかる。ところで、年齢別には、どうだろうか?
ggplot(data = covid) + stat_count(mapping = aes(x=age))と、Rに入力して、作成したグラフが以下である。
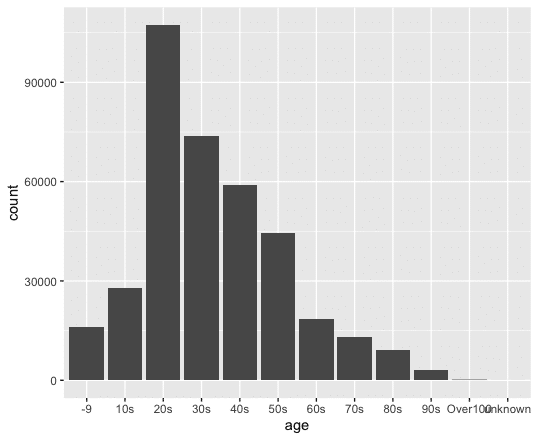
圧倒的に、20歳代(20s)の感染者が多いことがわかる。ところで、これは最近の話ではと思う方もいるだろう。では、20歳代の感染者は、初期段階に少なかったのか、2020年4月と、2021年8月の1ヶ月間の感染者数の年齢別の集計グラフを作成してみよう。
2020年4月
covid202004 <- covid %>% filter(date>="2020/4/1", date<="2020/4/30")
ggplot(data = covid202004) + stat_count(mapping = aes(x=age))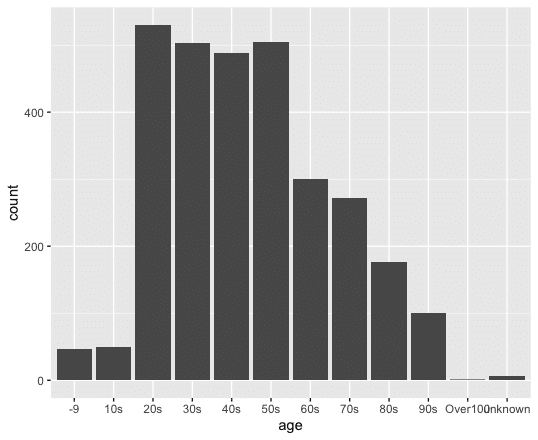
2021年8月
covid202108 <- covid %>% filter(date>="2021/8/1", date<="2021/8/31")
ggplot(data = covid202108) + stat_count(mapping = aes(x=age))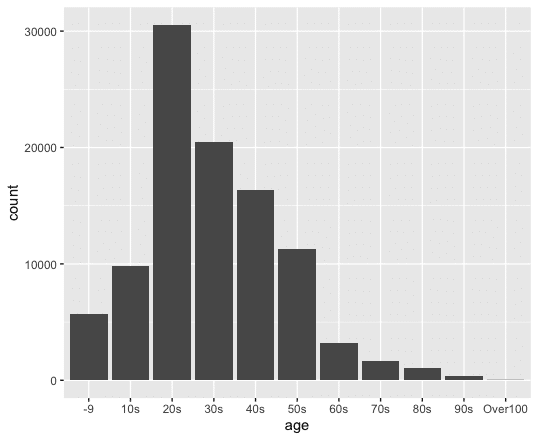
このようにデータを観察すると、高齢者にワクチン接種が進んだ、2021年8月では、20歳代の感染者数が、突出して多くいることがわかるが、初期段階である、2020年4月でも、20最大の感染者数は多いことがわかる。
このように、データを冷静に観察することが、データサイエンスの基本である。ぜひ、皆さんも、データを観察し、自分の行動のヒントにして欲しい。
いいなと思ったら応援しよう!
