

マクロデータでミクロな視点は持てない

先日、MarkeZineから受けた取材録が掲載されました。
デジタルマーケティングを扱う媒体の総本山に登場して、データを腐すなんて勇気の要る所業です。阪神ファンだらけの甲子園球場ライトスタンドで、私1人だけ巨人を応援するようなもの。何か1つ間違えれば血祭り…!
総スカンを食らうのではないかと心配して、めちゃくちゃエゴサーチしていたのですが、思ったより評判が良くて安心しました。それだけでなく、私と同じように考えている人が何人も居て心強いと思いました。
今回は取材録に対する反応を読み込んで「そういう考えがあるのか」と納得した幾つかのコメントを、自分なりの考えと咀嚼して混ぜ合わせて、まとめてみました。
データにおけるマクロな視点とミクロな視点
あまりお金をかけずデジタルマーケティングを始めるなら、広告はGoogle広告とFacebook広告、SEO対策を済ませたWEBサイトをGoogleAnalyticsとSearchConsoleで計測するのが一般的でしょうか。
それぞれの管理画面から全体の傾向が見えてきます。週ごとのCV件数、日ごとのPV数、時間ごとの表示回数…推移からトレンドを確認できます。こうしたデータは森全体(大勢)を見るためのマクロデータと定義します。
マクロデータを眺めていると、自然とCV件数に目が向きます。
購入してくれた人がいて、してくれなかった人がいる。なぜ買ってくれたのか、なぜ買ってくれなかったのか。1人1人の消費者の意思決定をデータで読み明かしたいと思うのは当然でしょう。
データから「◎◎だから買ってくれない」「◎◎だから買ってくれた」という明確な因果関係が伺える筋の良い仮説を発見し、機会を変えてまったく違う人で再現させて、購買意欲の向上を証明したいからです。
「因果関係が伺える筋の良い仮説」は凄く大事です。なぜなら「◎◎だから××してくれた」みたいな仮説を検証する際、答え合わせできる点が多いからです。
◎◎だから××してくれたのか、実は△△だから××してくれたのか。正解・不正解をチェックするポイントが多いほど、行動の理由を伺い知れます。
さらに次回以降に仮説を立てる際、前回の反省を踏まえてより堅牢な仮説が立てやすくなります。筋肉がより付く感じがしますね。
「打席に立て」とはよく言いますが、なぜボールに当たらなかったのだろうと残像から考えるのと、スイングの瞬間を録画し軌道を解析して「肘が上がり過ぎ?」「目線がぶれてる?」と仮説を立てるのでは、1回の打席の意味が変わってきます。
そうした機会に中々巡り合わない!という人もいるかもしれません。その意味において「#マーケティングトレース」は凄く大事な機会だと思います。長老の皆さまは「あんなのダメだ!」なんて思っているかもしれませんが。
解像度を高めるためにも、マーケター筋肉を鍛えるためにも、「因果関係が伺える筋の良い仮説」は凄く大事。大事なことなので二度言いましたよ。
そのために、森全体を見るためのマクロデータだけでなく、消費者に関するあらゆるデータ…つまり木一本(個人)を見るためのミクロデータが必要になってきます。
買った理由、買わなかった理由、好きなブランド、好きだったブランド、普段の行動、最近買ったお気に入り、好きな言葉、マイブーム、信念…。マクロデータと違って、ミクロデータは様々な種類が考えられますね。

でも、新たにミクロデータを計測するのは面倒臭いですよね。というか、何を計測すれば良いか、どういうデータが必要かが分からず迷ってしまう人もいるでしょう。
そこで、手元にあるマクロデータに目を向けます。マクロデータは森全体を表しているようで、1行1行は木を表しています。個人の行動履歴の積み重ねが週ごとのCV件数、日ごとのPV数、時間ごとの表示回数を表しているからです。

つまりミクロデータを新たに求めなくても、マクロデータを細分化して「個人レベル」にまで落とし込めば、必要最低限のミクロデータになるのではないか…と考えて行動に移った経験のある人、手をあげてください。
もちろん、私もその1人です。データベースからデータ引っこ抜いて、グリグリ回す個別案件やってました。
しかし考えてみて下さい。個人の行動の理由を洞察するために、森全体を見るためのマクロデータが最適でしょうか。ミクロ経済学やるのに、マクロ経済学で扱うデータを細分化すると言っているのと同義です。
システム開発で嫌と言うほど経験しましたが、「部分」を積み重ねても「全体」には到達しません。逆に、「全体」をどれほど細分化しても全ての「部分」が作られません。これは本当に不思議でした。
絶対に漏れるのです。つまり「部分だけ」「全体だけ」は不適切なのです。
まずはしっかり・入念・綿密に全体を設計した上で、次に部分を個別で設計し、最後に全体と部分の整合性を重ねて、ようやく要件定義〜設計が完成します。
それでも漏れ・不整合が起こるんですけどね。本当に開発は難しい…。
データも同じではないでしょうか?
GoogleAnalyticsにしろGoogle広告にしろ、管理画面で確認できる「大勢を見るためのマクロデータ」を、セグメントや時間で区切ってクロス集計したとしても、十分なミクロデータにはなりません。「1人に細分化されたマクロデータ」に過ぎないのです。
中には、そうしたデータだけで洞察に妄想の輪をかけて「これがオレの仮説だ!」と解決に導く凄腕祈祷師のようなマーケターもいます。否定はしません。しかし汎用的では無いし、再現性に欠けます。
このような現状が「データから分かる内容は限られている」論に拍車をかけるのだと思います。つまりはマイクロデータだけでは筋の良い仮説が立てられない、解像度の高い仮説が立てられないのです。
「何を知りたいか」で必要なデータは変わるはず
「目的」の無いデータ分析はありません。以下は、以前刊行した「これからのデータサイエンスビジネス」に掲載した「データ分析のプロセス」です。
1番上を見て下さい。「目的を定義する」後に、必要なデータはあるか?と問いを投げかけています。
つまり、分析の目的に応じて必要なデータは変わります。データが無ければ計測から始めます。目的に合わせてデータが生まれるのです。

B2Bビジネスにおいて、従量課金サービスの「売上予測」を目的とするモデルを作成した経験があります。大勢の動向を扱うマクロデータと、個別の動きを扱うミクロをミックスさせた、ちょっと複雑なモデルでした。
売上、リード件数は当然計測できているとして、1商談あたりの訪問回数、訪問ごとの確度、かかった時間などはセールスフォースを使って0から計測を始めました。結構大変で、本当大変で、泣くほど大変でした。
「1商談におけるN回目訪問の確度」なんてデータ、売上予測モデルでしか使えなさそうですね。その後、商談毎の最新の確度が分かってちょうど良いですみたいな話も聞きましたが、それは偶然の産物です。
目的も無く「1商談におけるN回目訪問の確度」なんてデータ、絶対に作らないでしょう。セールス部隊が手間だと反発します。つまり、データは目的が定義するのです。
手元にあるデータで偶然まかなえた…という場合も当然あります。それは、似たような目的で採掘したデータだった、と考えた方が良いでしょう。
私たちは「なぜ、この人はコンバージョンしてくれないのか?」という分析の目的に沿うデータを集めているでしょうか。手元にあるデータで済ませているから、結果的に「何も分からない」のではないでしょうか。
大事なことなので二度言いましたよ。
列を求めるビッグデータは成功するのか?
「1人に細分化されたマクロデータ」の解像度を高めるために、シングルソースパネルに代表されるような、1個人の情報をひたすらリッチにしようとする動きがあります。
CDPを導入して3rdデータを購入したり、会員登録したユーザーにアンケートを実施したりして、個人のデモグラフィック情報や趣味・嗜好を計測し、データとして登録する企業も増えています。
行を追加するのではなく、データ項目(列)を追加して、個人の情報を追加していく流れは加速する一方です。日経新聞「データの世紀」が、その動向を適時キャッチアップしていますよね。
私は「行を求めるビッグデータ」から「列を求めるビッグデータ」と表現しています。とにかくSyncしまくって、行の積み重ねだけでは見えなかった個人を丸裸にしようとする。

悪くは無いんでしょうが、もし「列を追うビッグデータ」が勝ち筋なら、先行していたはずのCCC(Tカード)が大失速する理由は何故でしょうか。どこ行っても「ポイントカードお持ちですか?」と聞かれますが、発行主で成功している企業ってどこでしょうか。
いや、あった方が良いとは思います。そこは否定しません。
あるオウンドメディアの閲覧傾向を「趣味」でクロス集計して、滞在時間や直帰率に如実に影響が現れたので「アウトドアが好きな人向けの企画を考えたら良いかもしれません」なんて話をした記憶はあります。まだグランピングとかが流行る前でした。
性別・年齢や年収、資料請求CVの有無で、最終的な商談のCVRが大きく違うと気付いた機会もあります。
しかし、それらはあくまで集団であって個人ではない。
集団のデータで「◎◎だから買ってくれない」「◎◎だから買ってくれた」という仮説を発見する機会も当然あります。しかし、傾向や特徴は単なる疑似相関で因果関係では無かった…なんて話よくあります。
私、クレイトン・クリステンセン、64歳。身長203センチメートル。靴のサイズは16(約32センチメートル)。妻と私は子ども全員を大学に進学させた。ボストン郊外に住み、ホンダのミニバンで通勤している。ほかにもたくさんの特徴と属性がある。だが、けさニューヨーク・タイムズ紙を買うという行動を私に選択させたのは、こうした特徴のせいではない。これらの特徴のあいだには相関があるのかもしれないし、ニューヨーク・タイムズ紙を買うのはたんなる習慣かもしれないが、こうした特徴が私に同紙を―ほかのどんな商品も―買わせるのではない。
ジョブ理論は、クリステンセン教授のこんな言葉から始まります。特徴が行動を生むわけではない、とはその通りですね。
「列を求めるビッグデータ」には、マクロデータを細分化しクロス集計を行うための列と、個人の行動の理由を追い求める列(これがミクロデータじゃないかと)と、2種類に分かれます。これは解法の違いだと考えています。
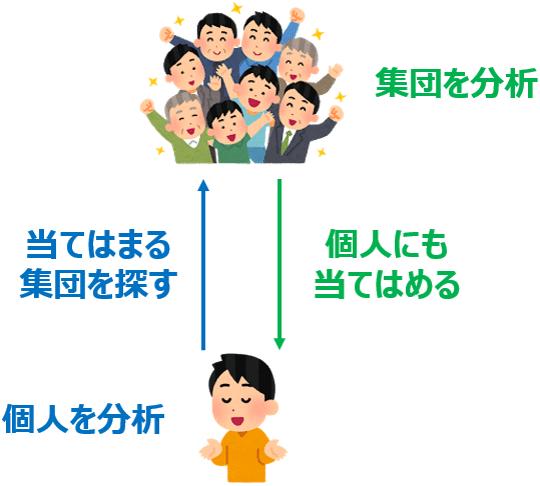
私自身、長らく右側の分析をやってきました。これが「マクロデータを細分化しクロス集計を行うための列」です。
でも、どうにも無理があると思う機会がしばしばありました。集団と個人には乖離があるのです。かつクリステンセン教授の言うように、集団の属性の違いを購買行動に求めがちですが、往々にしてそれが「相関」なのです。
疑似相関にはならないデータを求めて外部とSyncしても、一定以上は仮説の解像度をあげられないと気付きました。だから「個人の行動の理由を追い求める列」を求めてインサイトを学ぼうと決意しました。
仮説の解像度を爆上げナイトプールぱしゃぱしゃ
個人の行動の理由を追い求めるデータとして、やはり便利なのはマーケティングリサーチです。定量調査ではなく、定性調査が良いでしょう。
ここは若干のポジショントークがあるかもしれません。その辺は間引いて話を聞いて頂ければ幸いです。
グループインタビューでもいいですし、デプスインタビューでも良いです。1人の消費者と向き合い、買った理由、買わなかった理由を炙り出し、その理由が全体に当てはまるのかを考えてみましょう。
がっつりお金をかけようとすると100万以上はかかります。そんなお金は出せない、と思われたなら「周りの人に聞く」でも良いでしょう。
あるスマホアプリの改善分析に携わっていた時に、そのアプリがどんなフォルダ名で格納されているかで消費者がどう捉えているか分かるよね、と話した機会があります。
「どうしてフォルダ名は"日常系"なんですか?」
という質問から、その人にとっての日常と、スマホアプリがもたらす価値がどのように摺り合わさっているかを知れました。
こうして得たデータを、集団レベルに細分化されたマクロデータと組み合わせて洞察していく…これがいま巷で叫ばれている「定性と定量の両輪」なのかもしれません。
いいなと思ったら応援しよう!
